
4311 KB

1714 KB

1583 KB

2395 KB

1810 KB

4402 KB
We present an approach to visual tracking based on dividing a target into multiple regions, or fragments. The target is represented by a Gaussian mixture model in a joint feature-spatial space, with each ellipsoid corresponding to a different fragment. The fragments are automatically adapted to the image data, being selected by an efficient region-growing procedure and updated according to a weighted average of the past and present image statistics. Modeling of target and background are performed in a Chan-Vese manner, using the framework of level sets to preserve accurate boundaries of the target. The extracted target boundaries are used to learn the dynamic shape of the target over time, enabling tracking to continue under total occlusion. Experimental results on a number of challenging sequences demonstrate the effectiveness of the technique.
The visual tracking approach based on GMM modeling of the object and the level set framework can be summarized as follows:
Initial Frame:
Below are some experiments showing the tracker's performance on multi-modal objects, objects undergoing drastic shape changes and large unpredictable frame-to-frame motion. We also handle full occlusion. To accomplish this, the shape of the object contour is learned over time by retaining the output of the tracker in each image frame. To detect occlusion, the rate of decrease in the object size is determined over the previous few frames. Once the object is determined to be occluded, a search is performed in the learned database to find the contour that most closely matches the one just prior to the occlusion using a Hausdorff distance. Then as long as the target is not visible, the subsequent sequence of contours occurring after the match is used to hallucinate the contour. Once the target reappears, tracking resumes. This approach prevents tracker failure during complete occlusion and predicts contours when the motion is periodic. Click on any of the images to download its corresponding MPEG file.
| MPEG video clip | Description |
|---|---|
4311 KB |
Tickle Me Elmo doll: The benefit of using a multi-modal framework is clearly shown, with accurate contours being computed despite the complexity in both the target and background as Elmo stands tall, falls down, and sits up. |
1714 KB |
Monkey sequence: A sequence in which a monkey undergoes rapid motion and drastic shape changes. For example, as the monkey swings around the tree, its shape changes substantially in just a few image frames, yet the algorithm is able to remain locked onto the target as well as compute an accurate outline of the animal. |
1583 KB |
Walk behind tree sequence: A sequence in which a person walks behind a tree in a complex scene with many colors. Our approach predicts both the shape and the location of the object and displays the contour accordingly during the complete occlusion. |
|
2395 KB |
Girl sequence: A more complex scenario where a girl, moving quickly in a circular path (a complete revolution occurs in just 35 frames), is occluded frequently by a boy. Our approach is able to handle this difficult scenario. |
1810 KB |
Walk behind car sequence: A sequence in which a person is partially occluded by a car. Though we do not handle partial occlusion, the tracker adjusts the contour to only the visible portions of the moving person. Note that though the contours are extracted accurately for the body of the person, there are some errors in extracting the contours for the face region due to the complexity of the skin color. |
4402 KB |
Fish sequence: The fish are multicolored and swim in front of a complex, textured, multicolored background. Note that the fish are tracked successfully despite their changing shape. |
| Original BMP Sequence | Ground Truth Data | Comparison Results | Normalized Error Plot |
|---|---|---|---|
 19504 KB |
 48 KB |
 3127 KB |
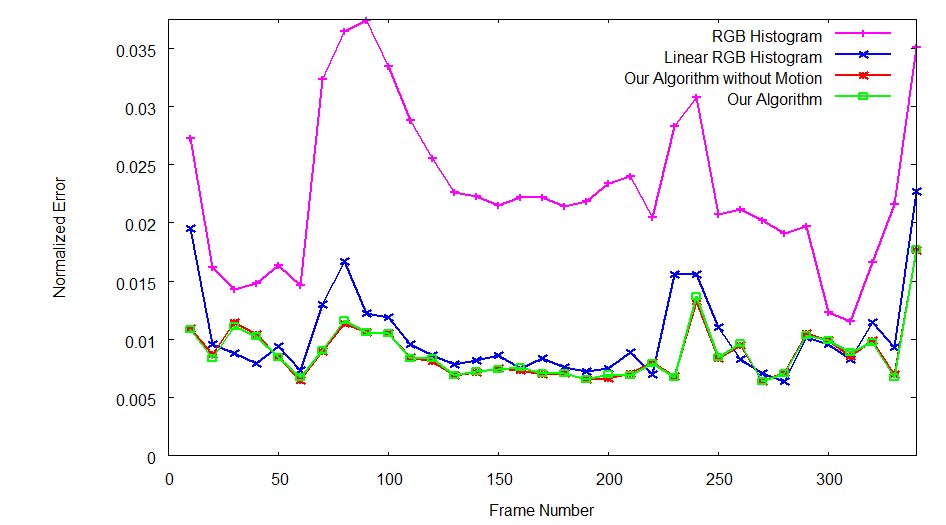
|
 17635 KB |
 52 KB |
 2019 KB |
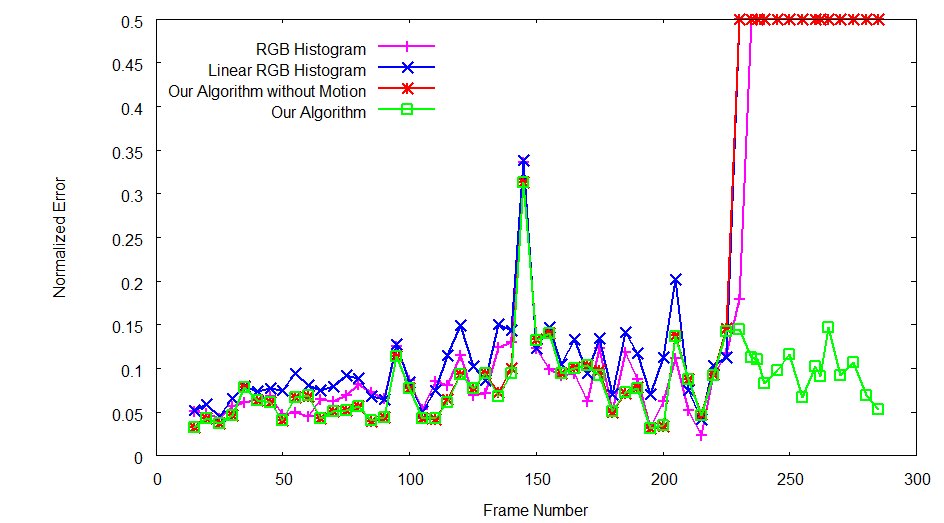
|
 23576 KB |
 25 KB |
 1186 KB |
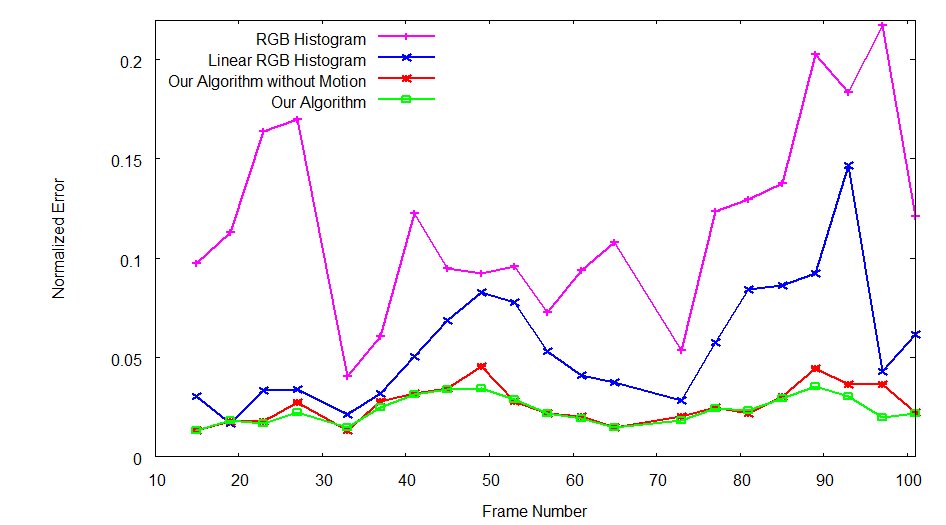
|
 33464 KB |
 22 KB |
 806 KB |
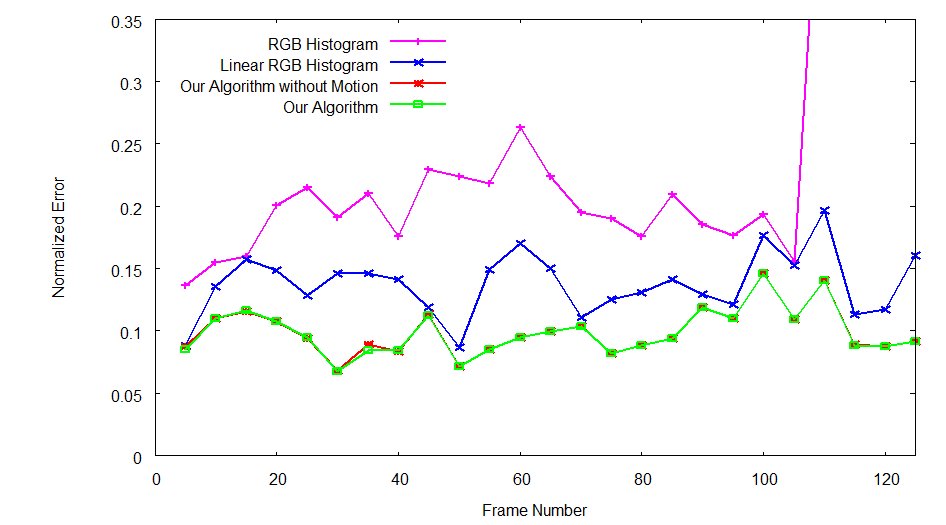
|
 42417 KB |
 49 KB |
 1693 KB |
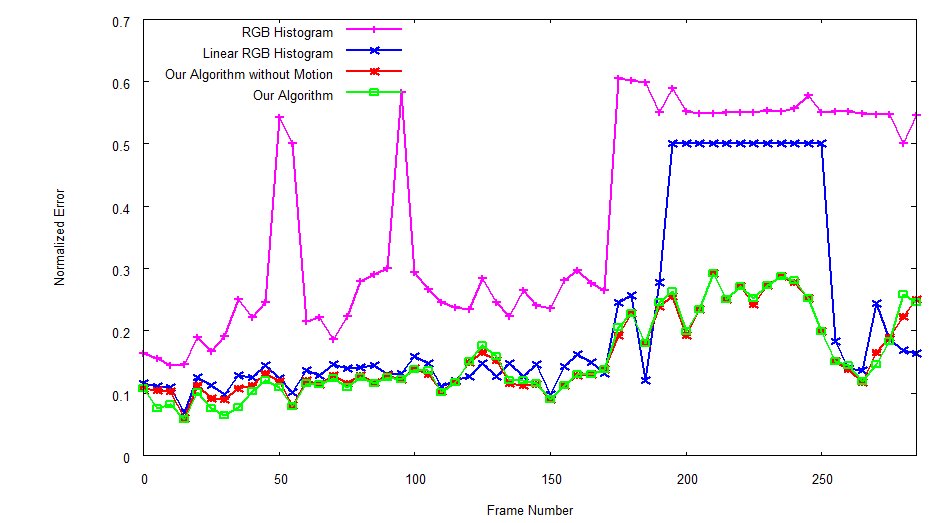
|