



Common fate, also known as common motion, is a powerful cue for image understanding. As a result, the ability to segment images based upon pixel motion is important for automated image analysis. Previous approaches process image sequences in bath, often assuming the motion of objects to be constant or slowly changing throughout the frames under consideration. We have developed a method for incremental motion segmentation that is independent of the image velocities of the objects in the scene because it takes into account all of the information from previous frames. The algorithm operates in real time and can handle an arbitrary number of groups.
The algorithm works as follows. Feature points are detected and tracked using the Kanade-Lucas-Tomasi (KLT) algorithm, then grouped using an affine motion model on the displacements of the coordinates of the features. Region growing is applied to the motion displacements by selecting a random seed point and then progressively growing the new group by including the neighboring features whose motion fits an affine motion model. Neighbors are determined using a Delaunay triangulation, and the affine model is constantly updated as new features are added to the group. This procedure is repeated on ungrouped features until all the groups have been found. The growing of a single group is shown below:.
The output of the grouping just described is highly dependent upon the initial seed point. As an example, the figure below shows different results from computing a single group from different seed points. The amount of variation is significant, but the intersection of all of the groups yields a consistent set of pixels which are always grouped together, no matter the seed point.





Top: Different results for a group using different seed points. Bottom: The intersection of these groups.
Now we illustrate the effects of the seed points upon finding multiple groups. After selecting a seed point and growing a single group, an ungrouped feature is selected as a new seed point and another group is grown. This process repeats until all features are grouped. The figure below shows four different results for four different seed points. Although the statue is always detected, sometimes the grass is merged with the trees, and sometimes the wall is merged with the trees. In each of these cases, just three groups are found.




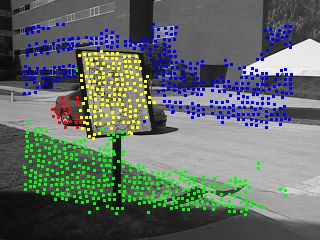
A consistency check is applied to the groups resulting from a number of different seed points. Consistent groups are determined as maximal sets of features which always belong to the same group, no matter the seed point. In the figure below, four consistent groups are correctly found, despite the fact that the initial results usually detected only three groups. Notice that the results agree with the image data on the number of objects in the scene and their locations.

One of the advantages of the proposed algorithm is its lack of parameters. The primary parameter, which was set to the same value for all these sequences, governs the amount of image evidence needed before features are declared to be moving consistently with one another. The same parameter is also used to determine when to split an existing group. Significantly, the results are insensitive even to this parameter: Increasing it causes the algorithm to simply wait longer before declaring a group, while decreasing it causes the groups to be declared sooner. The algorithm is fast, requiring only 20 ms per frame (excluding feature tracking, which can be made real time) for a sequence of 320×240 images with 1000 features on a 2.8 GHz P4 computer using an unoptimized C++ implementation.
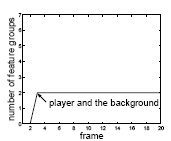
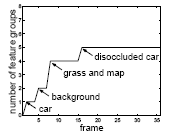
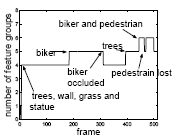
The algorithm, which automatically and dynamically determines the number of groups, was tested on four grayscale image sequences. The number of feature groups are plotted versus time below:

Videos showing the results:

|

|
|
|
statue sequence |
mobile-calendar sequence |
car-map sequence |
S. J. Pundlik and S. T. Birchfield,
Motion Segmentation at Any Speed,
Proceedings of the British Machine Vision Conference (BMVC), Edinburgh,
Scotland, September 2006.